 01
01 Shopper Sentiment Analysis
Actionable retail insights derived from live in-store video streams.
- Problem
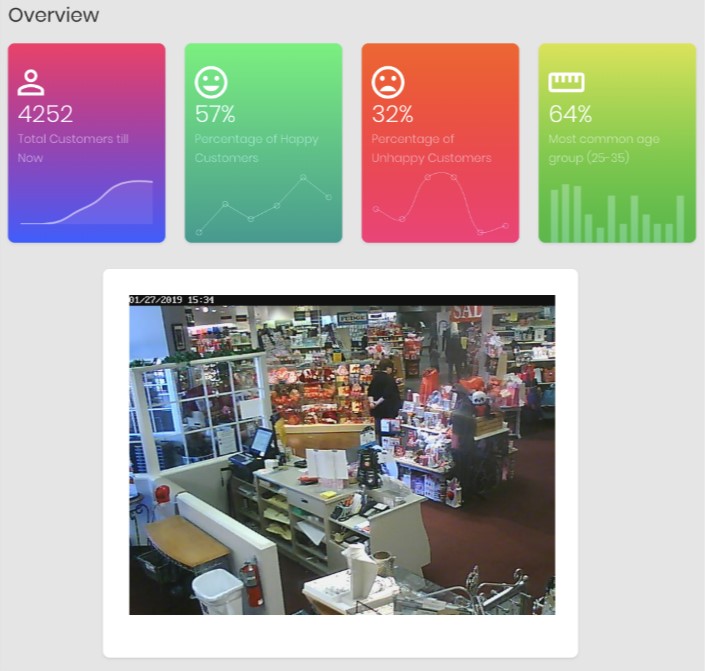
- Brick-and-mortar retailers have rich in-store behavior happening in front of cameras every day, but almost none of it is captured as data. Store owners couldn't answer basic questions: which aisles draw the most traffic, who their shoppers are, or how customers actually feel while browsing.
- Approach
- Built a pipeline that ingests live store video and applies managed ML vision services to detect foot-traffic hotspots, segment shoppers by demographic (approximate age, gender), and infer sentiment from facial expression — turning raw footage into a queryable stream of behavioral signals.
- Impact
-
- Surfaced high- vs. low-traffic zones to inform product placement
- Demographic segmentation of store traffic in near real time
- TODO: add a hard metric (e.g. frames/sec processed, accuracy, cost per store/day)
- AWS Rekognition
- AWS Lambda
- S3
- Python